WHERE子句
本书前面已经接触过WHERE子句的用法,这一节将详细讨论WHERE子句中查询条件的构成。WHERE子句必须紧跟FROM子句之后,在WHERE子句中,使用一个条件从FROM子句的中间结果中选取行。其基本格式为:
WHERE where_definition
其中,where_definition为查询条件。语法格式为:
where_definition:
<precdicate>
|<precdicate>{ AND | OR } <precdicate>
|(where_definition)
|NOT where_definition
其中,predicate为判定运算,结果为TRUE、FALSE或UNKNOWN。
<predicate>:
expression { = | < | <= | > | >= | <=> | <> | !=} expression /*比较运算*/
|match_expression [ NOT ] LIKE match_expression [ ESCAPE 'escape_character ' ]
/*LIKE运算符*/
|match_expression [ NOT ][ REGEXP | RLIKE ] match_expression
/*REGEXP运算符*/
|expression [ NOT ] BETWEEN expression AND expression /*指定范围*/
| expression IS [ NOT ] NULL /*是否空值判断*/
|expression [ NOT ] IN ( subquery | expression [,…n] ) /*IN子句*/
|expression { = | < | <= | > | >= | <=> | <> | !=} { ALL| SOME | ANY } ( subquery )
/*比较子查询*/
|EXIST ( subquery ) /*EXIST子查询*/
WHERE子句会根据条件对FROM子句的中间结果中的行一行一行地进行判断,当条件为TRUE的时候,一行就被包含到WHERE子句的中间结果中。
说明:
IN关键字既可以指定范围,也可以表示子查询。
在SQL中,返回逻辑值(TRUE或FALSE)的运算符或关键字都可称为谓词。
判定运算包括比较运算、模式匹配、范围比较、空值比较和子查询。
1. 比较运算
比较运算符用于比较两个表达式值,MySQL支持的比较运算符有:=(等于)、<(小于)、<=(小于等于)、>(大于)、>=(大于等于)、<=>(相等或都等于空)、<>(不等于)、!=(不等于)。
比较运算的语法格式为:
expression { = | < | <= | > |>= | <=> | <> | != } expression
其中expression是除TEXT和BLOB外类型的表达式。
当两个表达式值均不为空值(NULL)时,除了“<=>”运算符,其他比较运算返回逻辑值TRUE(真)或FALSE(假);而当两个表达式值中有一个为空值或都为空值时,将返回UNKNOWN。
MySQL有一个特殊的等于运算符“<=>”,当两个表达式彼此相等或都等于空值时,它的值为TRUE,其中有一个空值或都是非空值但不相等,这个条件就是FALSE。没有UNKNOWN的情况。
查询XS表中备注为空的同学的情况。
SELECT 姓名,学号,出生日期,总学分
FROM XS
WHERE 备注<=>NULL;
从查询条件的构成看出,可以将多个判定运算的结果通过逻辑运算符(AND、OR、XOR和NOT)组成更为复杂的查询条件。有关逻辑运算符,第6章会具体介绍。
查询XS表中专业为计算机,性别为女(0)的同学的情况。
SELECT 姓名,学号,性别,总学分
FROM XS
WHERE 专业名='计算机'AND 性别=0;
查询结果为:

2. 模式匹配
(1)LIKE运算符
LIKE运算符用于指出一个字符串是否与指定的字符串相匹配,其运算对象可以是char、varchar、text、datetime等类型的数据,返回逻辑值TRUE或FALSE。LIKE谓词表达式的格式为:
match_expression [ NOT ] LIKEmatch_expression [ ESCAPE 'escape_character' ]
使用LIKE进行模式匹配时,常使用特殊符号_和%,可进行模糊查询。“%”代表0个或多个字符,“_”代表单个字符。
escape_character:转义字符,escape_character 没有默认值,且必须为单个字符。当要匹配的字符串中含有与特殊符号(_和%)相同的字符时,此时应通过该字符前的转义字符指明其为模式串中的一个匹配字符。使用关键字ESCAPE可指定转义符。
由于MySQL默认不区分大小写,要区分大小写时需要更换字符集的校对规则。
查询XSCJ数据库XS表中姓“王”的学生学号、姓名及性别。
SELECT 学号,姓名,性别
FROM XS
WHERE 姓名 LIKE '王%';
执行结果为:
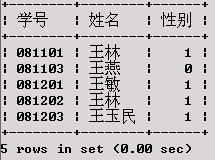
查询XSCJ数据库XS表中学号倒数第二个数字为0的学生学号、姓名及专业名。
SELECT 学号,姓名,专业名
FROM XS
WHERE 学号 LIKE '%0_';
执行结果为:

如果我们想要查找特殊符号中的一个或全部(_和%),我们必须使用一个转义字符。
查询XS表中名字包含下画线的学生学号和姓名。
SELECT 学号,姓名
FROM XS
WHERE 学号 LIKE '%#_%'ESCAPE '#';
说明:由于没有学生满足这个条件,所以这里没有结果返回。定义了“#”为转义字符以后,语句中在“#”后面的“_”就失去了它原来特殊的意义。
(2)REGEXP运算符
REGEXP运算符用来执行更复杂的字符串比较运算。REGEXP是正则表达式(regularexpression)的缩写。和LIKE运算符一样,REGEXP运算符有多种功能,但它不是SQL标准的一部分,REGEXP运算符的一个同义词是RLIKE。
语法格式:
match_expression [ NOT ][ REGEXP | RLIKE ]match_expression
LIKE运算符有两个符号具有特殊的含义:“_”和“%”。而REGEXP运算符则有更多的符号有特殊的含义,参见表4.11。
查询姓李的同学的学号、姓名和专业名。
USE XSCJ
SELECT 学号,姓名,专业名
FROM XS
WHERE 姓名 REGEXP '^李';
执行结果:

查询学号里包含4、5、6的学生学号、姓名和专业名。
SELECT 学号,姓名,专业名
FROM XS
WHERE 学号 REGEXP'[4,5,6]';
执行结果为:

查询学号以08开头,以08结尾的学生学号、姓名和专业名。
SELECT 学号,姓名,专业名
FROM XS
WHERE 学号 REGEXP'^08.*08$';
执行结果为:

3. 范围比较
用于范围比较的关键字有两个:BETWEEN和IN。
当要查询的条件是某个值的范围时,可以使用BETWEEN关键字。BETWEEN关键字指出查询范围,格式为:
expression [ NOT ] BETWEEN expression1 ANDexpression2
当不使用NOT时,若表达式expression的值在表达式expression1与expression2之间(包括这两个值),则返回TRUE,否则返回FALSE;使用NOT时,返回值刚好相反。
注意:expression1的值不能大于expression2的值。
使用IN关键字可以指定一个值表,值表中列出所有可能的值,当与值表中的任一个匹配时,即返回TRUE,否则返回FALSE。使用IN关键字指定值表的格式为:
expression IN ( expression [,…n])
查询XSCJ数据库XS表中不在1989年出生的学生情况。
SELECT学号, 姓名, 专业名, 出生日期
FROM XS
WHERE 出生日期 NOTBETWEEN '1989-1-1' and '1989-12-31';
执行结果为:

查询XS表中专业名为“计算机”、“通信工程”或“无线电”的学生的情况。
SELECT *
FROM XS
WHERE 专业名 IN ('计算机', '通信工程', '无线电');
该语句与下列语句等价:
SELECT *
FROM XS
WHERE 专业名 ='计算机'OR 专业名 = '通信工程' OR 专业名 = '无线电';
说明:IN关键字最主要的作用是表达子查询。
4. 空值比较
当需要判定一个表达式的值是否为空值时,使用IS NULL关键字,格式为:
expression IS [ NOT ] NULL
当不使用NOT时,若表达式expression的值为空值,返回TRUE,否则返回FALSE;当使用NOT时,结果刚好相反。
查询XSCJ数据库中总学分尚不定的学生情况。
SELECT *
FROM XS
WHERE 总学分 IS NULL;
本例即查找总学分为空的学生,结果为空。
5. 子查询
在查询条件中,可以使用另一个查询的结果作为条件的一部分,例如,判定列值是否与某个查询的结果集中的值相等,作为查询条件一部分的查询称为子查询。SQL标准允许SELECT多层嵌套使用,用来表示复杂的查询。子查询除了可以用在SELECT语句中,还可以用在INSERT、UPDATE及DELETE语句中。子查询通常与IN、EXIST谓词及比较运算符结合使用。
(1)IN子查询
IN子查询用于进行一个给定值是否在子查询结果集中的判断,格式为:
expression [ NOT ] IN ( subquery )
其中,subquery是子查询。当表达式expression与子查询subquery的结果表中的某个值相等时,IN谓词返回TRUE,否则返回FALSE;若使用了NOT,则返回的值刚好相反。
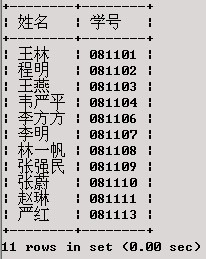
查找在XSCJ数据库中选修了课程号为206的课程的学生的姓名、学号。
SELECT 姓名,学号
FROMXS
WHERE学号 IN
(SELECT 学号
FROMXS_KC
WHERE课程号 = '206'
);
查询结果如下:
说明:在执行包含子查询的SELECT语句时,系统先执行子查询,产生一个结果表,再执行查询。本例中,先执行子查询:
SELECT 学号
FROM XS_KC
WHERE 课程号= '206';
得到一个只含有学号列的表,XS_KC中的每个课程名列值为206的行在结果表中都有一行。再执行外查询,若XS表中某行的学号列值等于子查询结果表中的任一个值,则该行就被选择。
注意:IN子查询只能返回一列数据。对于较复杂的查询,可以使用嵌套的子查询。
查找未选修离散数学的学生的姓名、学号、专业名。
SELECT 姓名,学号,专业名
FROMXS
WHERE学号 NOT IN
(
SELECT学号
FROMXS_KC
WHERE课程号 IN
(SELECT 课程号
FROMKC
WHERE 课程名 ='离散数学'
)
);
执行结果为:

(2)比较子查询
这种子查询可以认为是IN子查询的扩展,它使表达式的值与子查询的结果进行比较运算,格式为:
expression { < | <= | = | > |>= | != | <> } { ALL | SOME | ANY } ( subquery )
其中,expression为要进行比较的表达式,subquery是子查询。ALL、SOME和ANY说明对比较运算的限制。
如果子查询的结果集只返回一行数据时,可以通过比较运算符直接比较。
ALL指定表达式要与子查询结果集中的每个值都进行比较,当表达式与每个值都满足比较的关系时,才返回TRUE,否则返回FALSE;
SOME或ANY是同义词,表示表达式只要与子查询结果集中的某个值满足比较的关系时,就返回TRUE,否则返回FALSE。
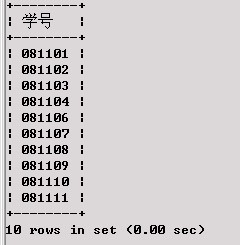
查找选修了离散数学的学生学号。
SELECT 学号
FROMXS_KC
WHERE 课程号 =
(
SELECT课程号
FROMKC
WHERE 课程名 ='离散数学'
);
查询结果为:
查找XS表中比所有计算机系的学生年龄都大的学生学号、姓名、专业名、出生日期。
SELECT 学号, 姓名, 专业名, 出生日期
FROMXS
WHERE 出生日期 <ALL
(
SELECT出生日期
FROMXS
WHERE专业名 ='计算机'
);
执行结果为:

查找XS_KC表中课程号206的成绩不低于课程号101的最低成绩的学生的学号。
SELECT 学号
FROMXS_KC
WHERE课程号 ='206' AND 成绩 >=ANY
(
SELECT成绩
FROMXS_KC
WHERE课程号 ='101'
);
执行结果为:
(3)EXISTS子查询
EXISTS谓词用于测试子查询的结果是否为空表,若子查询的结果集不为空,则EXISTS返回TRUE,否则返回FALSE。EXISTS还可与NOT结合使用,即NOT EXISTS,其返回值与EXIST刚好相反。格式为:
[ NOT ] EXISTS ( subquery )
查找选修206号课程的学生姓名。
SELECT 姓名
FROM XS
WHERE EXISTS
(
SELECT *
FROM XS_KC
WHERE 学号 = XS.学号 AND 课程号 = '206'
);
执行结果为:

分析:
① 本例在子查询的条件中使用了限定形式的列名引用XS.学号,表示这里的学号列出自表XS。
② 本例与前面的子查询例子不同点是,前面的例子中,内层查询只处理一次,得到一个结果集,再依次处理外层查询;而本例的内层查询要处理多次,因为内层查询与XS.学号有关,外层查询中XS表的不同行有不同的学号值。这类子查询称为相关子查询,因为子查询的条件依赖于外层查询中的某些值。其处理过程是:首先查找外层查询中XS表的第一行,根据该行的学号列值处理内层查询,若结果不为空,则WHERE条件就为真,就把该行的姓名值取出作为结果集的一行;然后再找XS表的第2、3、…行,重复上述处理过程直到XS表的所有行都查找完为止。
查找选修了全部课程的同学的姓名。
SELECT 姓名
FROM XS
WHERE NOT EXISTS
(
SELECT *
FROM KC
WHERE NOT EXISTS
( SELECT *
FROM XS_KC
WHERE 学号=XS.学号 AND 课程号=KC.课程号
)
);
说明:由于没有人选了全部课程,所以结果为空。
MySQL区分了4种类型的子查询:返回一个表的子查询是表子查询;返回带有一个或多个值的一行的子查询是行子查询;返回一行或多行,但每行上只有一个值的是列子查询;只返回一个值的是标量子查询。从定义上讲,每个标量子查询都是一个列子查询和行子查询。上面介绍的子查询都属于列子查询。
另外,子查询还可以用在SELECT语句的其他子句中。
表子查询可以用在FROM子句中,但必须为子查询产生的中间表定义一个别名。
从XS表中查找总学分大于50的男同学的姓名和学号。
SELECT 姓名,学号,总学分
FROM ( SELECT姓名,学号,性别,总学分
FROM XS
WHERE 总学分>50
) AS STUDENT
WHERE 性别='1';
查询结果:
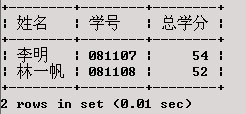
说明:在这个例子中,首先处理FROM子句中的子查询,将结果放到一个中间表中,并为表定义一个名称STUDENT,然后再根据外部查询条件从STUDENT表中查询出数据。另外,子查询还可以嵌套使用。
SELECT关键字后面也可以定义子查询。
从XS表中查找所有女学生的姓名、学号,以及与081101号学生的年龄差距。
SELECT 学号, 姓名, YEAR(出生日期)-YEAR(
(SELECT 出生日期
FROM XS
WHERE 学号='081101'
) ) AS 年龄差距
FROM XS
WHERE 性别='0';
查询结果:

说明:本例中子查询返回值中只有一个值,所以这是一个标量子查询。YEAR函数用于取出DATE类型数据的年份。
在WHERE子句中还可以将一行数据与行子查询中的结果通过比较运算符进行比较。
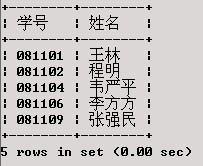
查找与081101号学生性别相同、总学分相同的学生学号和姓名。
SELECT 学号,姓名
FROM XS
WHERE (性别,总学分)=( SELECT 性别,总学分
FROM XS
WHERE 学号='081101'
);
查询结果:
分享到:




相关推荐
基于springboot的java毕业&课程设计
1.版本:matlab2014/2019a/2021a 2.附赠案例数据可直接运行matlab程序。 3.代码特点:参数化编程、参数可方便更改、代码编程思路清晰、注释明细。 4.适用对象:计算机,电子信息工程、数学等专业的大学生课程设计、期末大作业和毕业设计。
卷积神经网络(Convolutional Neural Networks, CNNs 或 ConvNets)是一类深度神经网络,特别擅长处理图像相关的机器学习和深度学习任务。它们的名称来源于网络中使用了一种叫做卷积的数学运算。以下是卷积神经网络的一些关键组件和特性: 卷积层(Convolutional Layer): 卷积层是CNN的核心组件。它们通过一组可学习的滤波器(或称为卷积核、卷积器)在输入图像(或上一层的输出特征图)上滑动来工作。 滤波器和图像之间的卷积操作生成输出特征图,该特征图反映了滤波器所捕捉的局部图像特性(如边缘、角点等)。 通过使用多个滤波器,卷积层可以提取输入图像中的多种特征。 激活函数(Activation Function): 在卷积操作之后,通常会应用一个激活函数(如ReLU、Sigmoid或tanh)来增加网络的非线性。 池化层(Pooling Layer): 池化层通常位于卷积层之后,用于降低特征图的维度(空间尺寸),减少计算量和参数数量,同时保持特征的空间层次结构。 常见的池化操作包括最大池化(Max Pooling)和平均池化(Average Pooling)。 全连接层(Fully Connected Layer): 在CNN的末端,通常会有几层全连接层(也称为密集层或线性层)。这些层中的每个神经元都与前一层的所有神经元连接。 全连接层通常用于对提取的特征进行分类或回归。 训练过程: CNN的训练过程与其他深度学习模型类似,通过反向传播算法和梯度下降(或其变种)来优化网络参数(如滤波器权重和偏置)。 训练数据通常被分为多个批次(mini-batches),并在每个批次上迭代更新网络参数。 应用: CNN在计算机视觉领域有着广泛的应用,包括图像分类、目标检测、图像分割、人脸识别等。 它们也已被扩展到处理其他类型的数据,如文本(通过卷积一维序列)和音频(通过卷积时间序列)。 随着深度学习技术的发展,卷积神经网络的结构和设计也在不断演变,出现了许多新的变体和改进,如残差网络(ResNet)、深度卷积生成对抗网络(DCGAN)等。
运行程序 1、测试.pt模型文件 1.在pycharm里打开下载的yolov5环境,在根目录打开runs文件,找到trains文件中的best_1.pt即为训练最优模型。 2.在根目录找到 detect.py 文件,修改代码221行默认路径至模型路径,222行路径更改至所需测试图片路径,点击运行。 2、测试.onnx模型文件 1.在pycharm里打开下载的yolov5环境,在根目录打开 export.py 文件,修改默认输出模型类型为onnx,选择best_1.pt输入模型,点击运行。 2.在根目录找到detect_onnx.py文件,修改代码221行默认路径至模型路径,222行路径更改至所需测试图片路径,点击运行。
基于springboot的java毕业&课程设计
华为桌面云解决方案 桌面云架构VDI和IDV VDI:虚拟桌面架构。特点是计算和数据都在云端,集中管理,集中运行。 IDV:智能桌面虚拟化。特点是镜像集中管理,计算和数据还是在终端,集中管理,分散运行。 (从方案的主推厂商看, 业界华为、思杰、Vmware(IDC国内桌面云市场份额排名前三)都主推VDI,目前推IDV架构的只有锐捷、噢易等少数国内厂商)
基于springboot的java毕业&课程设计
基于OpenCV的交通路口红绿灯控制系统设计 python毕业设计-源码+全部数据+使用文档(高分项目).zip本资源中的源码都是经过本地编译过可运行的,评审分达到95分以上。资源项目的难度比较适中,内容都是经过助教老师审定过的能够满足学习、使用需求,如果有需要的话可以放心下载使用。 【备注】 1、该项目是个人高分毕业设计项目源码,已获导师指导认可通过,答辩评审分达到95分 2、该资源内项目代码都经过测试运行成功,功能ok的情况下才上传的,请放心下载使用! 3、本项目适合计算机相关专业(如软件工程、计科、人工智能、通信工程、自动化、电子信息等)的在校学生、老师或者企业员工下载使用,也可作为毕业设计、课程设计、作业、项目初期立项演示等,当然也适合小白学习进阶。 4、如果基础还行,可以在此代码基础上进行修改,以实现其他功能,也可直接用于毕设、课设、作业等。 基于OpenCV的交通路口红绿灯控制系统设计 python毕业设计-源码+全部数据+使用文档(高分项目).zip基于OpenCV的交通路口红绿灯控制系统设计 python毕业设计-源码+全部数据+使用文档(高分项目).zip基于Op
课设毕设基于SSM的知识产权管理系统源码可运行.zip
卷积神经网络(Convolutional Neural Networks, CNNs 或 ConvNets)是一类深度神经网络,特别擅长处理图像相关的机器学习和深度学习任务。它们的名称来源于网络中使用了一种叫做卷积的数学运算。以下是卷积神经网络的一些关键组件和特性: 卷积层(Convolutional Layer): 卷积层是CNN的核心组件。它们通过一组可学习的滤波器(或称为卷积核、卷积器)在输入图像(或上一层的输出特征图)上滑动来工作。 滤波器和图像之间的卷积操作生成输出特征图,该特征图反映了滤波器所捕捉的局部图像特性(如边缘、角点等)。 通过使用多个滤波器,卷积层可以提取输入图像中的多种特征。 激活函数(Activation Function): 在卷积操作之后,通常会应用一个激活函数(如ReLU、Sigmoid或tanh)来增加网络的非线性。 池化层(Pooling Layer): 池化层通常位于卷积层之后,用于降低特征图的维度(空间尺寸),减少计算量和参数数量,同时保持特征的空间层次结构。 常见的池化操作包括最大池化(Max Pooling)和平均池化(Average Pooling)。 全连接层(Fully Connected Layer): 在CNN的末端,通常会有几层全连接层(也称为密集层或线性层)。这些层中的每个神经元都与前一层的所有神经元连接。 全连接层通常用于对提取的特征进行分类或回归。 训练过程: CNN的训练过程与其他深度学习模型类似,通过反向传播算法和梯度下降(或其变种)来优化网络参数(如滤波器权重和偏置)。 训练数据通常被分为多个批次(mini-batches),并在每个批次上迭代更新网络参数。 应用: CNN在计算机视觉领域有着广泛的应用,包括图像分类、目标检测、图像分割、人脸识别等。 它们也已被扩展到处理其他类型的数据,如文本(通过卷积一维序列)和音频(通过卷积时间序列)。 随着深度学习技术的发展,卷积神经网络的结构和设计也在不断演变,出现了许多新的变体和改进,如残差网络(ResNet)、深度卷积生成对抗网络(DCGAN)等。
基于springboot的java毕业&课程设计
房地产企业财务风险的成因与防范对策-以万科集团为例.docx
基于springboot的java毕业&课程设计
基于springboot的java毕业&课程设计
基于springboot的java毕业&课程设计
基于Python+定向爬虫的商品比价系统的实现的设计与实现+详细文档+全部资料(高分毕业设计).zip本资源中的源码都是经过本地编译过可运行的,评审分达到95分以上。资源项目的难度比较适中,内容都是经过助教老师审定过的能够满足学习、使用需求,如果有需要的话可以放心下载使用。 【备注】 1、该项目是个人高分毕业设计项目源码,已获导师指导认可通过,答辩评审分达到95分 2、该资源内项目代码都经过测试运行成功,功能ok的情况下才上传的,请放心下载使用! 3、本项目适合计算机相关专业(如软件工程、计科、人工智能、通信工程、自动化、电子信息等)的在校学生、老师或者企业员工下载使用,也可作为毕业设计、课程设计、作业、项目初期立项演示等,当然也适合小白学习进阶。 4、如果基础还行,可以在此代码基础上进行修改,以实现其他功能,也可直接用于毕设、课设、作业等。基于Python+定向爬虫的商品比价系统的实现的设计与实现+详细文档+全部资料(高分毕业设计).zip本资源中的源码都是经过本地编译过可运行的,评审分达到95分以上。资源项目的难度比较适中,内容都是经过助教老师审定过的能够满足学习、使用需求。
MySQL8.4.0 LTS(mysql-8.4.0-solaris11-sparc-64bit.tar)适用于Oracle Solaris 11 (SPARC)
反弹shell
植物保护-深度学习-YOLOv5-病虫害识别训练数据集是一个精心策划的数据集,旨在为农业科技领域的研究人员提供强大的工具,以改善病虫害的识别和管理工作。数据集包含了10000张高清图像,覆盖了10余种常见的植物病虫害,每一张图像都经过了专业标注,确保了数据的质量和准确性。 为了进一步提升模型的泛化能力和鲁棒性,数据集经过了数据增强处理,包括随机旋转、翻转、缩放和裁剪等多种变换,从而扩大了训练数据的多样性。这种增强处理有助于模型学习到更多的特征,提高其在实际应用中的表现。 此数据集适用于深度学习框架YOLOv5,它是一个高效的目标检测模型,能够实时地识别和定位图像中的病虫害。通过使用这个数据集,研究人员可以训练和优化YOLOv5模型,使其在病虫害的早期检测和防治中发挥关键作用。 植物保护-深度学习-YOLOv5-病虫害识别训练数据集的推出,不仅能够促进农业科技的发展,还能够帮助农业生产者更有效地管理作物健康,减少农药使用,保护环境,实现可持续农业。
MySQL8.4.0 LTS(mysql-server_8.4.0-1ubuntu22.04_amd64.deb-bundle.tar)适用于Ubuntu 22.04 Linux (x86, 64-bit)